GROUP BY | |||||
|
| ||||
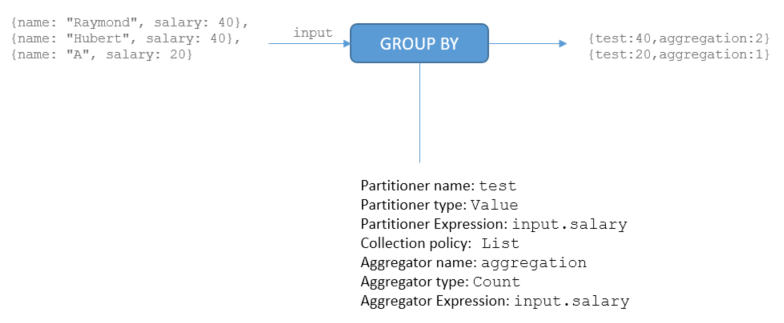
Partitioners
You specify how to partition the input stream with PartitioningFunction
objects. Define how you want to split your data before doing an aggregation. The
ValuePartitioningFunction is the most common one.
You can partition your data with multiple partitioners. When you do so, it applies the partitioners at the same level.
Example:
[
{age:21,surname:"martin",firstName:"Jean"},
{age:20,surname:"martin",firstName:"Pierre"},
{age:21,surname:"jack",firstName:"Paul"},
{age:20,surname:"jack",firstName:"Leo"},
{age:20,surname:"jack",firstName:"Jeanne"},
]
To split with two value partitioners surname and age, you
must have 4 data packages:
- First package:
{age:21,surname:"martin",firstName:"Jean"} - Second package:
{age:20,surname:"martin",firstName:"Pierre"}, - Third package:
{age:20,surname:"jack",firstName:"Leo"}, {age:20,surname:"jack",firstName:"Jeanne"}, - Fourth package:
{age:21,surname:"jack",firstName:"Paul"},
The name of the partitioner is the variable name you can use in the outputExpression.
Aggregators
As for the AGGREGATE operator, you define the aggregations a with
AggregationFunction objects.
Output
The output is a stream of type: Tuple<KEY, AGGREG1, AGGREG2, ...>
The output stream cardinality corresponds to the number of groups found during the grouping
operation. The number of elements in the tuple corresponds to number_aggregations +
1 (KEY).
If you define both fast path aggregators and nested graphs, the output type is:
Tuple<KEY, AGGREGFASTPATH1, AGGREGFASTPATH2, ..., AGGREGGRAPH1, ...
>
Example
You want to group employees who share the same salary.