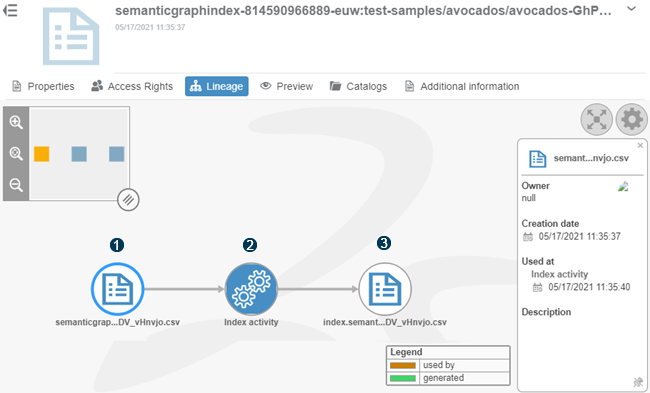
Prepare the Data Source Lineage in Datasets Governance
First prepare the data source lineage in Datasets Governance, by creating the catalog that will contain the datasets resulting from the Data Factory Studio pipeline (as explained in the next section).
- Required:
Create a catalog to register the data source.
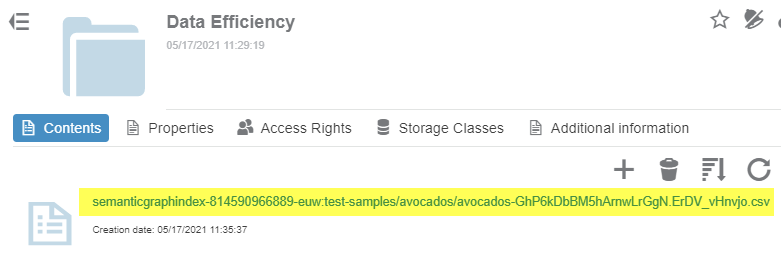
For example, if the data source is a CSV file in an S3 Storage, you must create a catalog mapping the S3 bucket folder containing this CSV file. In the following screenshot
Data Efficiencyis a folder on the S3.