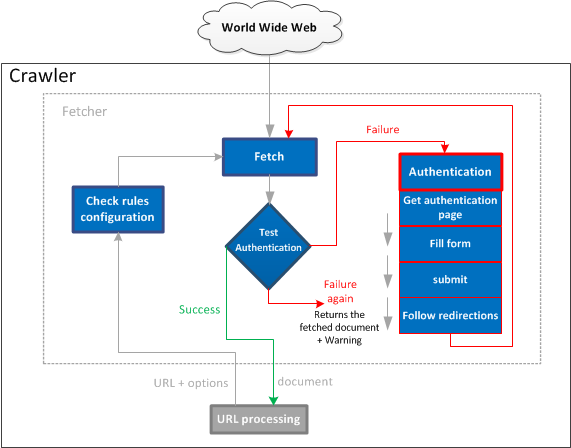
The crawler asks the fetcher for a URL. The crawler does not know
anything about authentication, and the fetcher does not know anything about the
URLs that must be crawled and crawl rules.
The fetcher tests whether the URL matches the authentication
configuration pattern.
The fetcher tries to fetch the URL a first time, without trying the
authentication process. If the session has already been opened and is still
active, a reauthentication is not required.
The fetcher tests the success/failure condition on the fetched document. If the
condition returns "success", this means that the page is correctly
authenticated, and is returned as is to the crawler.
Else, it means that the session has expired and the fetcher has to
reauthenticate:
First, it fetches the gateway as configured. It follows redirections as
required, until it finds an HTML page.
The login form is extracted from the HTML according to the
configuration.
The parameters are extracted from the form, and completed with the
username/password fields configured.
The form action is submitted with all these parameters.
Redirections are followed, with a limit to avoid loops. Redirections are
often used at this point to transfer authentication tokens to session
cookies (which can live on other domains).
Finally the fetcher tries to fetch the original URL a second time.
The success/failure condition is tested a second time: if the configuration is
correct, it returns "success".
If the condition is successful, the document is returned to the
crawler.
Else, the configuration is broken. A warning is printed in the
crawler process log, and the resulting document is still returned to the
crawler.