Impact Detection | ||
| ||
In the Consolidation Store, there are typically some documents that are linked with other documents, and some that are not. For the linked ones, we might want to aggregate/enrich some information from the structural properties present in these graphs.
For example, if you have document 1 that has an aggregation processor to collect all documents in purple, what will happen later on in the aggregation process if document 5 gets modified?
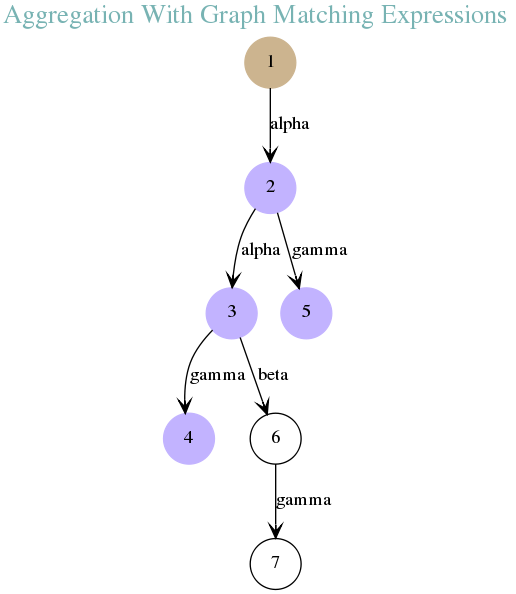
Since document 1 is collecting some information from document 5 to enrich its own metadata, you have to relaunch the aggregation on document 1. This is precisely what the impact detection algorithm does for you. The benefit of having such calculation happening for you undercover, is that you can code your aggregation processors (and your transformation processors) independently of the documents arrival order.
For more example of object graph matching expressions, see Appendix - Matching Expressions Grammar.
Internally, the Impact Detection algorithm is based on the strings that flow to the match operations. Consequently, every modification to your transformation and aggregation processor implementations that might change such strings, need a force aggregation action in the Administration Console or the API Console.
Two things may occur depending on how your trigger the action:
-
Either you apply the action on a subset of pushed documents, by including or excluding some URIs or types.
In that case, the internal state for the strings identified by Exalead CloudView stay as is. Keep in mind that if you choose this option, the behavior of the impact detection might be affected negatively. You might have missed to select documents that have to be reprocessed because of past modifications in the processors. If you know this is not the case, then the operation is safe.
-
Or you apply the action on the whole set of documents, without specifying any URIs or Types.
In such case, the Impact Detection reconstructs its appropriate internal states as expected. Such operation is safe in all cases.
In the contex of big bookmarks arborescence, you can reduce the number of impacted documents to reduce index latency.
When modifying or updating a document, one or more metas are changed, or one or more arcs are created or deleted in this document. Therefore, all documents below in the tree are reindexed.
To avoid reindexing all these documents, you can add a meta in addition to the name of the document to reduce the impact of update. For more information on the meta, see Appendix - Matching Expressions Grammar.
Thanks to this meta, there are less impactful aggregations, which results in smaller and faster jobs.