Step 1 - Define the Connectors Corresponding to Each Source
Create the Filesystem Connector
Before you begin:
In this use case, we have a very small set of PDF documents to push to the
Consolidation Server using the Files connector. To reproduce this example with a real
corpus, if your documents have large binary parts, the Consolidation Server cache ends
up with a disk footprint close to the size of the indexed corpus.
For real use cases, convert document binary parts before pushing documents into the
Consolidation Server:
- Go to the Advanced tab and a Convert PushAPI
Filter to the Files connector.
- Extract text content only (and exclude binary parts) by setting the
Conversion mode to Text.
-
In the Administration Console, go to Index > Connectors and click Add connector.
-
In Name, enter
countryfiles.
- For Type, select the Files connector.
- For Push to PAPI server, select the
Consolidation server cbx0 instance.
- Click Accept.
-
For Store documents in data model class, choose the document class.
-
In Filesystem paths, enter the following path: <INPUTDIR>/pdf
-
Click Save.
Create the Database Connector
-
In the Administration Console, go to Index > Connectors and click Add connector.
-
In Name, enter country.
- For Type, select the JDBC connector.
- For Push to PAPI server, select the
Consolidation server cbx0 instance.
- Click Accept.
-
For Store documents in data model class, choose the country class.
-
In Connection parameters:
- For Driver, enter org.sqlite.JDBC
- For Connection string, enter jdbc:sqlite://<INPUTDIR>/coffee.db
- Click Test connection. The database connector automatically connects to the database.
-
In Query parameters:
- For Synchronization mode, select Full synchronization
-
For Initial query, enter: Select country_id,
ico_status, name from countries
-
Click Retrieve fields.
-
Define the
country_id field as primary key.
-
Click the
country_id field to expand it.
-
Select Use as primary key.
-
Click Save.
Step 2 - Configure Consolidation
Configure the Transformation Processor
-
Go to Index > Consolidation
-
Add a new transformation processor:
- Select Groovy as format
- For Name, enter
Files
- Click Accept
-
For Source connector, select
countryfiles
-
Replace the default code by the following one:
Groovy code
// Process all nodes coming from the selected source connector
process("") {
// Extract the country id from the filename.
// For example, for "brazil.pdf", we want to extract "brazil".
String filename = it.metas.getValue("file_name");
def values = filename.split('\\.');
log.info "doc uri:[" + it.getUri() + "] countryId:[" + values[0] + "]";
// Link the filesystem document to its related “countries” database record.
// The default URI of a database record is: "<fieldname>=<value>&"
it.addArcFrom("describedBy", "country_id=" + values[0] + "&");
}
Java equivalent code
@Override
public void process(IJavaAllUpdatesTransformationHandler handler, IMutableTransformationDocument document) throws Exception {
document.setType("document");
final String filename = document.getMeta("file_name");
if (filename == null || filename.isEmpty()) {
throw new Exception("File name not available");
}
final String[] values = filename.split("\\.");
if (values == null || values.length == 0) {
throw new Exception("Invalid file name");
}
LOGGER.info("doc uri:[" + document.getUri() + "] countryId:[" + values[0] + "]");
document.addArcFrom("describedBy", "country_id=" + values[0] + "&");
}
With this transformation processor, we have achieved to link files to their related database records.
Configure the Aggregation Processor
-
Add an aggregation processor:
- Select Groovy as format
- For Name, enter Countries_UC_1
- Click Accept
-
Replace the default code by the following one:
Groovy code
// Process nodes having the “country” type
// The node type is deduced by the document class automatically
process("country") {
log.info "country found: " + it.metas.name;
// Find nodes related to the country
// Goal: Create a “country” consolidated document with information coming from the matched file.
it.metas.hasfile = "no";
for (path in match(it, "describedBy[document]")) {
// If a valid path is found, retrieve its last element
last = path.last()
log.info "File found: " + last.getUri();
// Retrieve the binary parts of the found nodes
// To get all parts: it.parts.getMap().putAll(last.parts.getMap());
// To get the master part only:
it.parts.master += last.parts.master;
it.metas.hasfile = "yes";
}
}
Java equivalent code
@Override
public void process(IJavaAllUpdatesAggregationHandler handler, IAggregationDocument document) throws Exception {
final String countryName = document.getMeta("name");
if (countryName == null || countryName.length() == 0) {
throw new Exception("Invalid country name '" + countryName + "'");
}
LOGGER.info("Country found: " + countryName);
// find document related to the country
// Goal: be able to consolidate information of pdf document with country database record
final List<IAggregationDocument> pathsEnds = GraphMatchHelpers.getPathsEnd(handler.match(document, "describedBy"));
for (IAggregationDocument file : pathsEnds) {
LOGGER.info("File found: " + file.getUri());
document.withPart("master", file.getPart("master"));
document.withMeta("hasfile", "yes");
}
}
-
Save and apply the configuration.
Note:
It is also possible to consolidate security tokens, using the security meta.
After it.metas.hasfile = "yes"; add it.metas.security += last.metas.security;
Step 3 - Scan Source Connectors and Check What Is Indexed
-
Go to the Home page and under the connectors list, click
Scan for the Files and JDBC connectors.
Note:
In the Connectors list, a consolidation-<instance
name> row displays status information about consolidation. All
documents and countries are indexed.
-
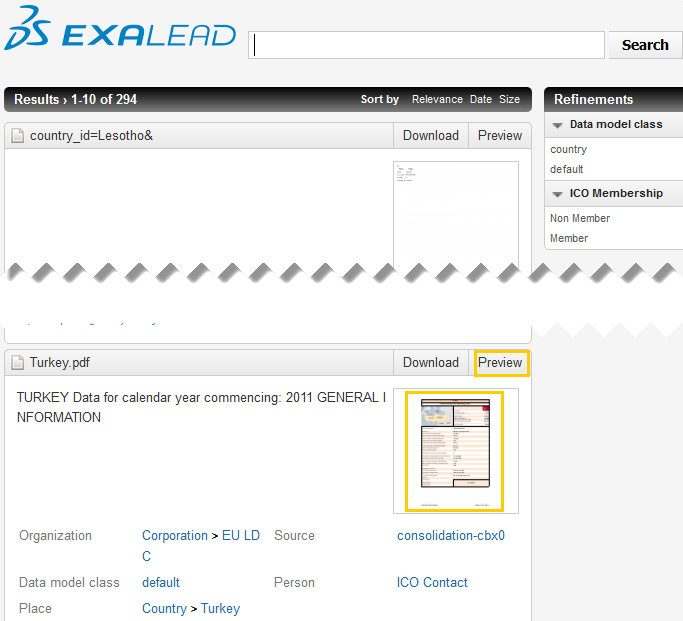
Open the Mashup UI application search page:
http://<HOSTNAME>:<BASEPORT>/mashup-ui/page/search
-
Check that country documents have associated parts (thumbnails/previews are
available).
-
To get a consolidated view, go to:
http://<HOSTNAME>:<BASEPORT>/mashup-ui/page/searchcountry_v1
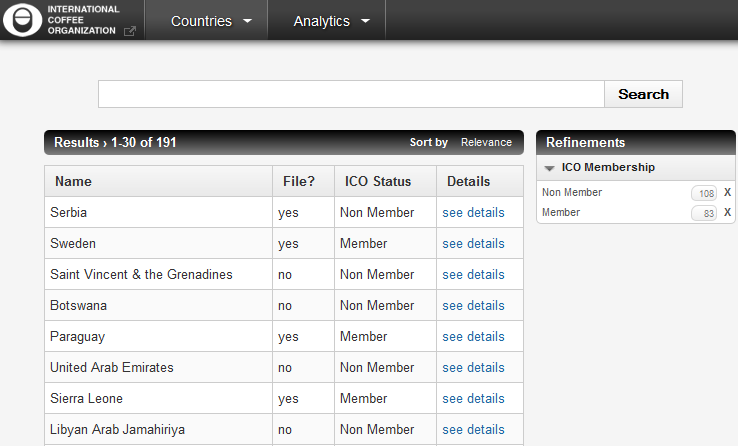
The following graphic shows what we achieved on the object graph.

|