Step 1 - Define the Source Connector for StorageService
-
In the Administration Console, go to Index > Connectors and click Add connector.
-
In Name, enter
storageService.
- For Type, select the JDBC connector.
- For Push to PAPI server, select the
Consolidation server cbx0 instance.
- Click Accept.
-
For Store documents in data model class, enter
storageValue.
Note:
This class is not present in the data model yet. It is only used by the
Consolidation Server.
-
In Connection parameters:
- For Driver, enter org.sqlite.JDBC
- For Connection string, enter jdbc:sqlite://<DATADIR>/storageService/storage.db.sqlite
- Click Test connection. The database connector automatically connects to the database.
-
In Query parameters:
- For Synchronization mode, select Query-based incremental synchronization
- For Initial query, enter:
select ikey, ukey, value, res_type, res_id, modified_date, source, app_id, build_group from cv360_storage_service
- For All URI Query, enter:
select ikey, ukey from cv360_storage_service
- For Checkpoint query, enter:
select max(modified_date) from cv360_storage_service
- For Incremental variable, enter:
TS
- For Incremental query, enter:
select ikey, ukey, value, res_type, res_id, modified_date, source, app_id, build_group from cv360_storage_service where modified_date > '$(TS)'
-
Click Retrieve fields.
-
Define the
ukey and ikey fields as primary
keys.
-
Click the
ukey field to expand it.
-
Select Use as primary key.
-
Repeat the operation for the
ikey field.
-
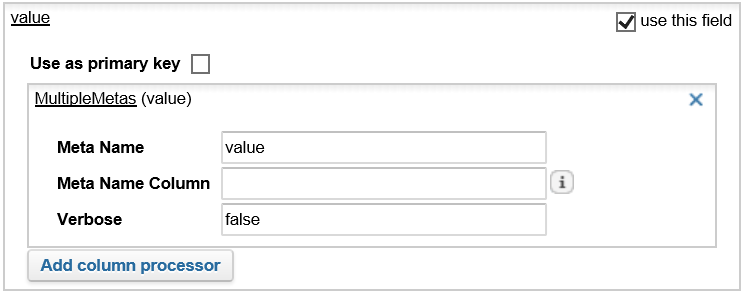
For the
value field:
-
Delete the automatic processor.
-
Click Add column processor and add a
MultipleMetas processor.
-
For Meta Name, enter
value.
-
Click Apply.
Step 2 - Link storageService Tags to Countries
Configure the Transformation Processor
-
Go to Index > Consolidation
-
Add a new transformation processor:
- Select Java as format.
- For Name, enter
StorageService.
- For Processor, select Storage Service Key Linker Processor.
- Click Accept.
-
For Source connector, select storageService
- Click Save.
With this processor, we have achieved to link storageService tags to
country documents.
Note:
To get the same result with Groovy code, replace the default code by the following one:
// Process all nodes
process("") {
// Logs the content of the document passing through this processor
log.info "Received document: " + it
// Adding parent type
it.setType("storageValue", "storage");
// Create the virtual object depending on the name used for storing tag values
// URI = <key store name (tags[] for example)> + delimiter + link object key (res_id)
// Type: "storage_" + key store name without [] (tags[] for example)
keystoreObject = createDocument( 'storageKey_' + it.metas.getValue("ikey") + "-#-"
+ it.metas.getValue("res_id"), // keystore URI
"storageKey_" + it.metas.getValue("ikey")[0..-3], "storage" // type
);
// Add key name to the document (for debugging purpose only)
// remove last 2 characters:[]
keystoreObject.metas.name = it.metas.getValue("ikey")[0..-3]
yield keystoreObject;
// Add link from keystore value to keystore object
it.addArcFrom('hasForValue', 'storageKey_' + it.metas.getValue("ikey") + "-#-"
+ it.metas.getValue("res_id"));
// Add link from keystore object to linked object
keystoreObject.addArcFrom('hasStorageKey', it.metas.getValue("res_id"));
}
Configure the Aggregation Processors
-
Add an aggregation processor:
- Select Java as format.
- For Name, enter Countries_UC_8.
- For Processor, select Storage Service Key Flattener Processor.
- Click Accept.
-
Configure the processor as follows:
- For Processed Document type, enter country.
- For Key store document type, enter storageKey_tags.
- For Target meta, enter tags.
Note:
To get the same result with Groovy code, replace the default code by the following one:
// Process nodes having the “country” type
process("country") {
// Add "tags[]" keystore values on countries
// by matching on nodes with the type [storageKey_tags]
// For other keys, use [storageKey_<whatever>]
for (node in (match(it, "hasStorageKey[storageKey_tags].hasForValue[storageValue]")*.last())) {
log.info "keystore value found : " + node.metas.getValues("value");
it.metas.tags.addAll(node.metas.getValues("value"))
}
log.info "country after tags : " + it
}
-
Add another aggregation processor to discard storage nodes:
- Select Java as format.
- For Name, enter Storage_UC_8.
- For Processor, select Discard.
- Click Accept.
-
For Discard document types, click Add item and enter storage.
Note:
To get the same result with Groovy code, replace the default code by the following one:
process("storage") {
log.info "discard for : " + it
// discard storage nodes
discard()
}
-
Save and apply the configuration.
Step 3 - Add Tags to Countries
-
Open the following Mashup UI application page:
http://<HOSTNAME>:<BASEPORT>/mashup-ui/page/searchcountry_v4
-
Search for a country, for example, Singapore .
-
Click the see details link.
-
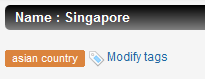
Click the Tag this country link to add a tag to the selected country. For example, for Singapore, enter asian country and press
ENTER.
asian country displays as tag.
 - Perform the 3 previous steps to tag Japan as asian country too.
Step 4 - Index Tags
-
Click Scan for the
storageService JDBC
connector and wait for data to be fully indexed.
Two documents are indexed for the storageService connector.
-
Open the Mashup UI application again:
http://<HOSTNAME>:<BASEPORT>/mashup-ui/page/searchcountry_v4
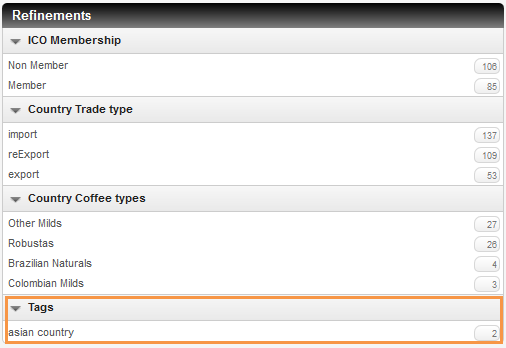
You can now see a new Tags facet in the Refinements panel, displaying the values entered for the tagged documents.
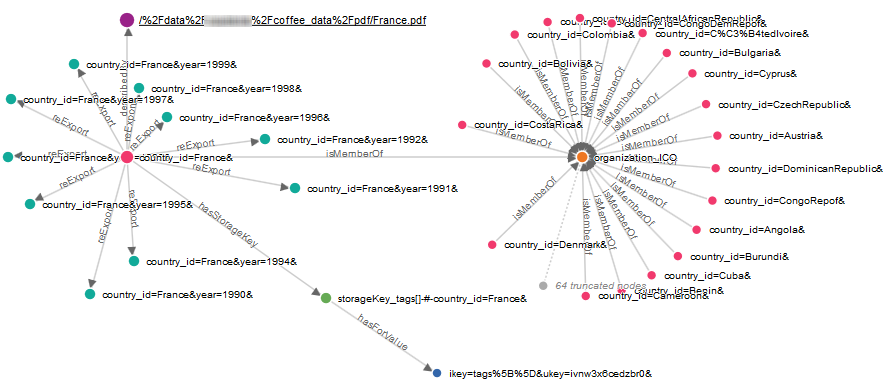
The following graphic shows what we achieved on the object graph (Max. arcs per node has been set to 10 for more readability).
|