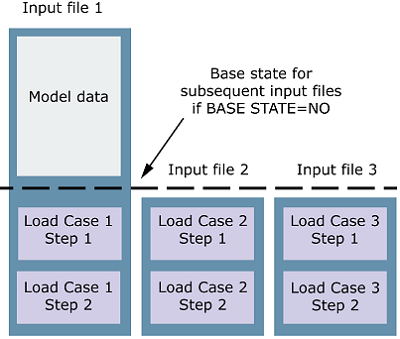
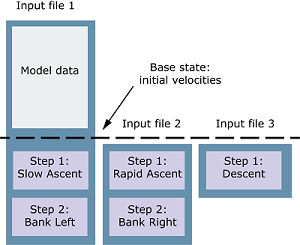
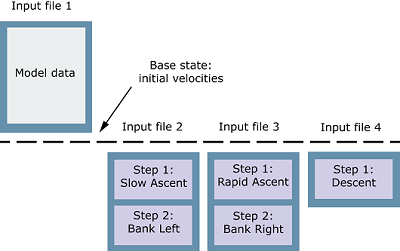
The following example shows a nonlinear load case analysis where the first input
file defines the model and the steps for the first nonlinear load case. Each
subsequent input file defines the steps for the next nonlinear load case.
MANIFEST, EVOLUTION TYPE=HISTORY, RESULTS=NEW, BASE STATE=NO
Data line to specify the input file defining the model and the first nonlinear load case
Data line to specify the input file defining the next nonlinear load case
…
The following example shows a nonlinear load case analysis where the first input
file defines the model and the base state for all nonlinear load cases. Each
subsequent input file defines the steps for the next nonlinear load case.
MANIFEST, EVOLUTION TYPE=HISTORY, RESULTS=NEW, BASE STATE=YES
Data line to specify the input file defining the model and the base state steps
Data line to specify the input file defining the first nonlinear load case
Data line to specify the input file defining the next nonlinear load case
…