Parallelization in Abaqus/Explicit is implemented in two ways: domain level and loop level. The default and most efficient
method is the domain-level parallelization method. It splits the model into topological
domains and assigns each domain to a processor. The loop-level method should be used only in
the rare cases where the domain-level method is not applicable or is inefficient. It
parallelizes low-level loops that are responsible for most of the computational cost. The
element, node, and contact pair operations account for the majority of the low-level
parallelized routines.
Parallelization is invoked by specifying the number of processors to use.
Domain-Level Parallelization
The domain-level method splits the model into a number of topological domains. These
parallel domains contain a subset of the nodes and elements and all the modeling features
necessary to compute the solution. The domains are distributed evenly among the available
processors. The analysis is then carried out independently in each domain. However,
information must be passed between the domains in each increment because the domains share
common boundaries. The domain-level method is supported with
MPI, thread-based parallelization, and in hybrid mode (a
combination of MPI and threads).
During initialization, the domain-level method divides the model so that the resulting
domains take approximately the same amount of computational expense. The load balance is
defined as the ratio of the computational expense of all domains in the most expensive
process to that of all domains in the least expensive process. For cases exhibiting
significant load imbalance, either because the initial load balancing is not adequate
(static imbalance) or because imbalance develops over time (dynamic imbalance), the dynamic
load balancing technique may be applied (see Abaqus/Standard and Abaqus/Explicit Execution).
Dynamic load balancing is based on over-decomposition: the user selects a number of domains
that is a multiple of the number of processors. During the calculation, Abaqus/Explicit will regularly measure the computational expense and redistribute the domains over the
processors so as to minimize the load imbalance. The following functionality is not
supported with dynamic load balancing:
The efficiency of the dynamic load balancing scheme depends on the load imbalance inherent
to the problem, on the degree of overdecomposition, and on the efficiency of the hardware.
Most imbalanced problems will see optimal performance improvement when the number of domains
is two to four times the number of processors. The efficiency may be significantly reduced
on systems with a slow interconnect, such as Gigabit Ethernet clusters. Best results are
obtained when an external interconnect is not needed, such as within a multicore node of a
cluster, or on a shared-memory system. Applications most likely to benefit from dynamic load
balancing are problems with a strongly time-dependent and/or spatially varying computational
load. Examples are models containing airbags (where contact-impact activity is highly
localized and time dependent) and coupled Lagrangean-Eulerian problems (where constitutive
activity follows the material as it moves through empty space).
Element and node sets are created for each domain. The sets are named domain_n,
where n is the domain number.
Thread-Based Execution
Abaqus/Explicit can be executed in thread mode within one node of a compute cluster and takes advantage
of the shared memory available to the threads that are running on different cores.
MPI-Based Execution
Abaqus/Explicit can be executed in MPI mode, which uses the message
passing interface (MPI) to communicate between processes
running on different cores that may be spread over multiple compute nodes on an HPC
cluster.
Hybrid Execution
Abaqus/Explicit can be executed in hybrid mode using a combination of
MPI and threads with each
MPI process launching a user-specified number of
threads. Execution in hybrid mode is invoked by setting the command line option
threads_per_mpi_process=m.
The number of cpus must be divisible by the number of threads per
MPI process.
Compute nodes of HPC clusters typically have more than one socket, with each socket
containing multiple cores. Each socket is physically designed with its own block of local
memory, where access to this memory is significantly faster than nonlocal (remote) memory.
This architecture is known as Non-Uniform Memory Access (NUMA). Hybrid execution takes
advantage of the NUMA architecture and the trend of increasing the number of cores
available on each socket. Therefore, the value for the threads per MPI process is
typically set to the number of cores available within a socket. Hybrid execution is
recommended only for jobs engaging one or more full compute nodes on a homogeneous
cluster. The processors per node (ppn) should to be set to the total number of cores
available on each compute node when submitting to a batch queuing system.
The number of domains is selected by Abaqus/Explicit automatically and does not need to be specified. If specified, Abaqus/Explicit may tune the number of domains for optimal performance. The number of domains is listed
in the status (job-name.sta) file.
Consistency of Results
The analysis results are independent of the number of processors used for the analysis.
However, the results do depend on the number of parallel domains used during the domain
decomposition. Except for cases in which the single- and multiple-domain models are
different due to features that are not yet available with multiple parallel domains
(discussed below), these differences should be triggered only by finite precision effects.
For example, the order of the nodal force assembly may depend on the number of parallel
domains, which can result in differences in trailing digits in the computed force. Some
physical systems are highly sensitive to small perturbations, so a tiny difference in the
force applied in one increment can result in noticeable differences in results in
subsequent increments. Simulations involving buckling and other bifurcations tend to be
sensitive to small perturbations.
To obtain consistent analysis results from run to run, the number of domains used in the
domain decomposition should be constant. Increasing the number of domains increases the
computational cost slightly; therefore, unless dynamic load balancing is being applied, it
is recommended that the number of domains be set equal to the maximum number of processors
used for analysis execution for optimal performance. If you do not specify the number of
domains, the number defaults to the number of processors.
Features That Do Not Allow Domain-Level Parallelization
The use of the domain-level parallelization method is not allowed with the following
features:
Extreme value output. An alternative is to filter the output.
Steady-state detection. This feature is typically used with ALE adaptive mesh
domains.
If you include these features, Abaqus issues an error message.
Features That Cannot Be Split across Domains
Certain features cannot be split across domains. The domain decomposition algorithm
automatically takes this into account and forces these features to be contained entirely
within one domain. If fewer domains than requested processors are created, Abaqus/Explicit issues an error message. Even if the algorithm succeeds in creating the requested
number of domains, the load may be balanced unevenly. If this behavior is not acceptable,
the job should be run with the loop-level parallelization method.
Adaptive smoothing domains cannot span parallel domain boundaries. The nodes on the
boundary between an adaptive smoothing domain and a nonadaptive domain as well as the
adaptive nodes on the surface of the adaptive smoothing domain cannot be shared with
another parallel domain. To enforce this in a consistent manner when parallel domains are
specified, all nodes shared by adjacent adaptive smoothing domains will be set as
nonadaptive. In this case the analysis results may be significantly different from that of
a serial run with no parallel domains. Set the number of parallel domains to 1, and switch
to the loop-level parallelization method if this behavior is undesirable. See Defining ALE Adaptive Mesh Domains in Abaqus/Explicit for details.
A contact pair cannot be split across parallel domains, but separate contact pairs are
not restricted to be in the same parallel domain. A contact pair that uses the kinematic
contact algorithm requires that all of the nodes associated with the involved surfaces be
within a single parallel domain and not be shared with any other parallel domains. A
contact pair that uses the penalty contact algorithm requires that the associated nodes be
part of a single parallel domain, but these nodes may also be part of other parallel
domains. Analyses in which a large percentage of nodes are involved in contact may not
scale well if contact pairs are used, especially with kinematic enforcement of contact
constraints. General contact does not limit the domain decomposition boundaries.
Nodes involved in kinematic constraints (About Kinematic Constraints), with the
exception of surface-based shell-to-solid constraints, will be within a single parallel
domain; and they will not be shared with another parallel domain. However, two kinematic
constraints that do not share nodes can be placed within different parallel domains.
In some cases beam elements that share a node may be forced into the same parallel
domain. This happens only for beams whose center of mass does not coincide with the
location of the beam node or for beams with additional inertia (see Adding Inertia to the Beam Section Behavior for Timoshenko Beams).
User Influence on Domain Decomposition
You can influence the domain decomposition by specifying one or more regions that are
independently decomposed into a user-specified number of parallel domains or by specifying
that an element set should be constrained to the same parallel domain.
Specifying a domain decomposition region can be useful when a local region of the model
is computationally intensive. Performance gains may be achieved by identifying the local
region as an independent domain decomposition region, thereby distributing computation of
the local regions among all processors. You can specify the domain decomposition region by
defining an element set directly, or Abaqus/Explicit can generate the domain decomposition region consisting of all
elements within a user-specified box. The part of the model that is not included in any
user-specified domain decomposition region is considered as the global region and is also
decomposed into the user-specified number of parallel domains. You can specify that each
decomposition region can be decomposed using a recursive coordinate bisection
(RCB) algorithm or a graph partitioning algorithm that
minimizes the number of shared nodes. The RCB algorithm
is the default for all domain decomposition regions. You can also specify that each domain
decomposition region can be decomposed into domains by specifying a decompose factor N. The
domains from each independent domain decomposition are distributed evenly among the
available processors, but these domains can be reassigned to different processors during
the analysis if dynamic load balancing is activated. The total number of parallel domains
for the simulation is
where
is the number of local regions identified as independent domain decomposition
regions;
is equal to 1 if any elements are not included in local regions identified as
independent domain decomposition regions; otherwise, is 0;
is the decompose factor for domain decomposition region ;
is the decompose factor for the global domain decomposition region; and
Separate domain decomposition regions may be desired, for example, in bird-strike models
(where contact-impact activity is highly localized and time dependent) and coupled
Eulerian-Lagrangian problems with localized adaptive mesh refinement (where elements are
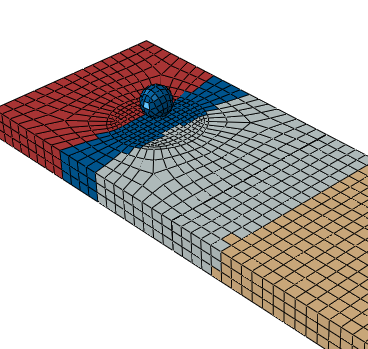
refined adding to the computational cost). The example below (Figure 1) shows a spherical projectile impacting a flat plate with a failure model, thus
allowing the projectile to perforate the plate. One of the domains contains the projectile
as well as a significant portion of the impact area. Specifying a domain decomposition
region consisting of the projectile as well as the computationally intensive impact area
results in a more balanced parallel processing (Figure 2). In this example and ; therefore, .
Original domain decomposition. Modified domain decomposition.
Multiple domain decomposition regions can be specified. In the case of overlap between
the domain decomposition regions, by default, the first specified decomposition keeps the
overlapped elements. Some modeling features cannot be split across domains, and Abaqus/Explicit automatically merges the domain decomposition regions that contain features that cannot
be split.
Restart
There are certain restrictions for restart when using domain-level parallelization. To
ensure that optimal parallel speedup is achieved, the number of processors used for the
restart analysis must be chosen so that the number of parallel domains used during the
original analysis can be distributed evenly among the processors. Because the domain
decomposition is based only on the features specified in the original analysis and steps
defined therein, features that affect domain decomposition are restricted from being
defined in restart steps only if they would invalidate the original domain decomposition.
Because the newly added features will be added to existing domains, there is a potential
for load imbalance and a corresponding degradation of parallel performance.
The restart analysis requires that the separate state and selected results files created
during the original analysis be converted into single files, as described in Abaqus/Standard and Abaqus/Explicit Execution. This should be done automatically at the conclusion
of the original analysis. If the original analysis fails to complete successfully, you
must convert the state and selected results files prior to restart. An Abaqus/Explicit analysis packaged to run with a domain-level parallelization technique cannot be
restarted or continued with a loop-level parallelization technique.
Co-Simulation
The co-simulation technique (About Co-Simulation) for run-time
coupling of Abaqus/Explicit to Abaqus/Standard or to third-party analysis programs can be used with Abaqus/Explicit running either in serial or parallel.
Loop-Level Parallelization
The loop-level method parallelizes low-level loops in the element and contact pair code
only. The speedup factor using loop-level parallelization may be significantly less than
what can be achieved with domain-level parallelization. The speedup factor will vary
depending on the features included in the analysis since not all features utilize parallel
loops. Examples are the general contact algorithm and kinematic constraints. The loop-level
method may scale poorly for more than four processors depending on the analysis. Using
multiple parallel domains with this method will degrade parallel performance and, hence, is
not recommended. The loop-level method is not supported on the Windows platform.
Analysis results for this method do not depend on the number of processors used.
Restart
There are no restrictions on features that can be included in steps defined in a restart
analysis when using loop-level parallelization. For performance reasons the number of
processors used when restarting must be a factor of the number of processors used in the
original analysis. The most common case would be restarting with the same number of
processors as used in the original analysis. An Abaqus/Explicit analysis packaged to run with a loop-level parallelization technique cannot be
restarted or continued with a domain-level parallelization technique.
Measuring Parallel Performance
Parallel performance is measured by comparing the total time required to run on a single
processor (serial run) to the total time required to run on multiple processors (parallel
run). This ratio is referred to as the speedup factor. The speedup factor will equal the
number of processors used for the parallel run in the case of perfect parallelization.
Scaling refers to the behavior of the speedup factor as the number of processors is
increased. Perfect scaling indicates that the speedup factor increases linearly with the
number of processors. For both parallelization methods the speedup factors and scaling
behavior are heavily problem dependent. In general, the domain-level method will scale to a
larger number of processors and offer the higher speedup factor.