About the Overall Document Lifecycle
This section explains the document lifecycle through the various components of the Indexing Server.
In the Push API Server
When connectors send documents to the Indexing Server, they first arrive into the Push API server (PAPI server) of the Indexing Server.
When you push a document to the Push API Server, it contains:
-
document URI
-
document stamp to indicate the version
-
meta data
-
parts containing the bytes from the document
-
directives for data extraction
In the Analysis Pipeline
Documents are then pushed to the analysis pipeline of the Indexing server.
The first step is to transform the content of the document parts and the metadata items into internal items that the document and semantic analysis processors can process. These internal items are called document chunks.
-
Each document chunk is tagged as a context which name is case-sensitive.
-
Created contexts depend on the extraction process. By default, it creates the
textandtitlecontexts for each part, and a context for each metadata item.
The following example shows the mapping of a document with one part and metadata items to several contexts.


Once the document is represented as contexts with one or more document chunks, the analysis processors can process it. The processors can perform one of the following:
-
create new contexts
-
transform existing contexts
If you want to perform semantic analysis, you must tokenize the context. The semantic processor can create annotations for the tokens. The following example shows a possible representation of the document after analysis.

In the Index
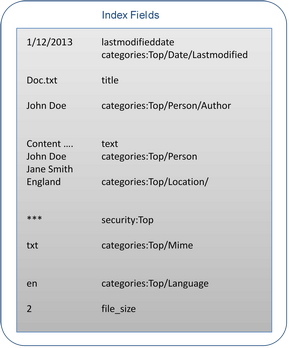
The final phase is the mapping of the contexts and the annotations to index fields so that the document may be used for search.
When a document matches a query the results contain hit fields, metadata (that can be different from the Push API metadata), categories, and related terms.