|
Automatic
|
Acts either like the Multiple Parts processor on
BINARY/BLOB values or like the Multiple Metas on all other
columns. If a meta is pushed, then its name is the value of the Meta
Name setting; if a part is pushed, its name is
master.
|
|
Average Meta
Max Meta
Min Meta
Total Meta
|
Calculates the average/maximum/minimum/total value of the
column and push the result as a meta with the name
Meta Name.
These processors accept the
Multiplier parameter. The result is
multiplied by the
Multiplier. This allows CloudView to
push double values (double or floating) as integers.
|
|
Concatenate as meta
|
Concatenates every value of the column and pushes the
resulting string as the
Meta Name
meta. It accepts the
separator parameter. The separator
value is inserted between the different row values.
|
|
Concatenate as part
|
Concatenates every value of the column and pushes the
resulting string as a part with the name
Part Name. It accepts the
separator parameter. The separator
value is inserted between the different row values.
|
|
Document Filter
|
Ignores or deletes the current document. It accepts the
Ignore Value and
Delete Value parameters.
When the value of the column equals the
Ignore Value (IGNORE by default), the
resulting PAPI document is not pushed.
When the value of the column equals the
Delete Value (DELETE by default), the
resulting PAPI document is deleted from the index.
|
|
File Attach Part
|
Pushes every value of the column as a part with the name
Part Name. It accepts the following
parameters:
-
Encoding - encoding hint added to
the resulting part.
-
Encoding Column - column
containing encoding hints added to the resulting part (overrides encoding).
-
Prefix - prepended to the file name when attempting to
load it.
-
Suffix - appended to the file name when attempting to
load it.
-
Mime - mime hint added to the
resulting part.
-
Mime Column - column containing
mime hints added to the resulting part (overrides mime).
|
|
First Value as Meta
Last Value as Meta
|
Pushes only the first/last value (respectively) of the
column as a meta with the name
Meta Name.
|
|
First Value as Part
Last Value as Part
|
Pushes only the first/last value (respectively) of the
column as a part with the name
Part Name.
|
|
Custom
|
Custom code processes every value of the column. The Class Id
parameter is the java class of the column processor. You can enter
additional parameters.
|
|
Map Value as Meta
|
Maps a column with a column found in another database (called satellite
database). The mapped values are then pushed as metas with the name
Meta Name. This processor accepts the following
parameters:
-
Class Name
Class of the satellite database
driver.
-
Connection String - connection string used to connect to the satellite database.
-
Query - query used to list the values of the satellite
table. This query produces results containing exactly two columns. The first
column contains values to be populated. The second column contains
replacement values.
-
Optional:
Login - login used when
connecting to the satellite database.
-
Optional:
Password - password used when
connecting to the satellite database.
Example:
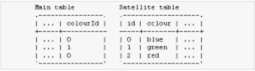
By attaching a
Map Value as Meta processor to the
column
colourId, and setting the satellite
query to:
SELECT id,colour FROM satelliteTable
This allows you to populate color ids with color names.
|
|
Multiple Metas
|
With this processor, every value of the column is pushed as
a separate meta value with the name
Meta Name.
|
|
Multiple Parts
|
With this processor, every value of the column is pushed as
a separate part. The first part is pushed with the name
Part Name. Subsequent parts are
numbered, for example,
Part Name is
master, subsequent parts are named
master_1, master_2.
This processor accepts the Filename Column parameter,
which designates a column that contains file names to be associated with pushed
parts.
|
|
Row Num URI
|
With this processor, an identifier (integer) is generated
and mapped automatically for each row of the tables that do not have a primary
key.
The enumeration order must stay stable over different enumerations. If not,
Document URIs may become different over time and updates are not reliable.
|
|
Unique Metas
|
With this processor, every unique value of the column is pushed as a separate
meta with the name Meta Name. This is the same as
Multiple Metas but duplicates are removed. Order of
values is kept.
|