Exalead CloudView
allows you to exploit huge quantities of both structured and unstructured data
coming from multiple data sources, to present it in an intuitive search
interface.
The
Exalead CloudView
platform uses textual and semantic technologies to reconcile formats,
structures and terminologies, and identify embedded meanings and relationships.
All information sources are unified in a robust modular index that ensures
continuous access and optimal use of server resources.
To start with a high-level view of the product, let us say that it is made of the following
parts:
Connectors to fetch data from data sources.
Indexing to process fetched documents and store them into the
index.
Searching to define how data will be searchable and what will be
displayed in the Search-Based Application.
Mashup UI or custom front-end applications based on search.
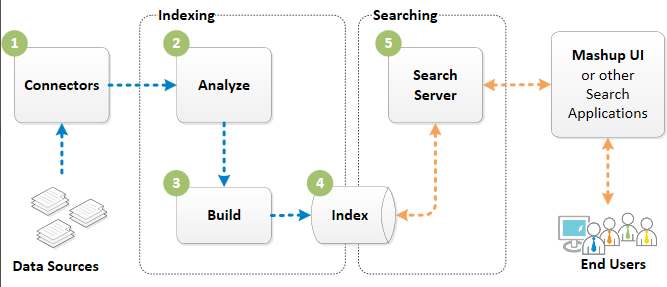
The following diagram summarizes the process to index and search with
Exalead CloudView.
A simplified view of
Exalead CloudView
#
Description
1
Connectors:
access the data sources,
fetch their files,
convert the files into documents,
send them to the Indexing Server through the Push API
protocol.
2
During the analysis phase, the Indexing Server:
Receives documents.
Triggers their analysis sequentially, entirely in memory.
The analyzers process each document in the analysis job, perform text
extraction, semantic processing, custom operations, and mapping.
3
During the build phase, the Indexing Server analyzes pushed documents, and
creates a new generation of the index. It creates a set of files (tables, inverted
list, and other structures) to make the index efficient at search time.
4
Once the build phase is complete, it is stored into the
index.
It merges the data computed for analysis with the current
version of the index.
Once done, the index is committed and updated. The new
documents are available for search.
5
The Search Server interprets and processes user queries.
Each user query is processed by the Search Server based on a
specific search logic.
6
Search queries and search results can be entered and
displayed either in the
Mashup UI (the default search application), or a custom search
application relying on the
Exalead CloudView Search API.
Exalead CloudView Software Interfaces
Main Software Interfaces
Exalead CloudView includes the following main software interfaces:
The following software interface extensions are available as
options. Contact your
NETVIBES representative for your licensing needs.
Mashup Builder Premium
Content Recommender extends the
Business Console with a business logic recommendation engine to recommend
results depending on a search query, for example, to recommend Home-cinemas
when the user searches for TV sets.
Add-ons
Add-ons
are optional components extending the capabilities of Exalead CloudView. You must install them in the INSTALLDIR. They require additional
installation steps and a product restart to be functional. Exalead CloudView add-ons include:
Extended Languages add-on extends semantic analysis for a wider
variety of languages.
Russian Lemmatization add-on allows Exalead CloudView to lemmatize Russian. As this language contains many inflections and therefore
involves a large resource, it is not shipped by default.
Exalead CloudView Terminology
Connectors provide access to your data source (files, records),
converts them into
Exalead CloudView documents, and then sends them to
Exalead CloudView for indexing. Connectors use the Push API (PAPI), a simple HTTP
API to feed the index with documents. Each connector relies on the data
source's native protocol to connect to its information source.
Convert allows
Exalead CloudView to read documents with various formats (such as PDF, XML, or
Microsoft Word). It receives documents from connectors, extract text and field
information from them, and pass that information along for indexing and storage
in the index.
Corpus refers to the collection of documents, coming from one or
several data sources that needs to be indexed.
Documents can be defined as all the objects to be indexed by
Exalead CloudView, regardless of file or entity type in the data source. For
example, HTML, JPG or CSV files, database records are all considered documents
within
Exalead CloudView, since they are all converted into a
Exalead CloudView-specific document format (also known as a
PAPI document) after being scanned by a connector.
Document metas, not to be confused with
hit metas, are pieces of text belonging to a document that have
associated values, such as title or size. Document metas are stored either as
an index field or as a category.
Context is sometimes used as a synonym for document meta.
Dictionary is a separate structure from the index that stores all the words from an
indexed document, plus their number of occurrences in the corpus. It is used for
linguistic expansion mechanisms such as spell-checking or regular expression matching.
Facets are used to narrow search results. Use them to drill down into an area, such as
language, author, or file type. They are typically used in dashboard analytics widgets,
or in the Refinements panel for enterprise search.
Hit metas, not to be confused with
documentmetas, are used to display one or more retrievable index
fields in the hit content of search results.
Index is an efficient structure used by
Exalead CloudView to store information about the items it has analyzed. When users
issue search queries,
Exalead CloudView quickly and easily finds the results within this structure.
The
Exalead CloudView index is divided into fields:
Each field has a type: alphanumeric, numeric, hierarchical categories, geographic,
and so forth.
Each field can be defined as:
Searchable
which means that user search queries can be applied to
this field.
Retrievable which means that the field can be
displayed in the search results.
Queries are the search requests sent to the
Exalead CloudView search engine and processed according to a specified search logic.
Thumbnails are small image previews for documents, which can be
displayed in the search results. They are computed at search-time and kept in
the browser cache for one week.