With the HA option, the resulting configuration has the following structure.
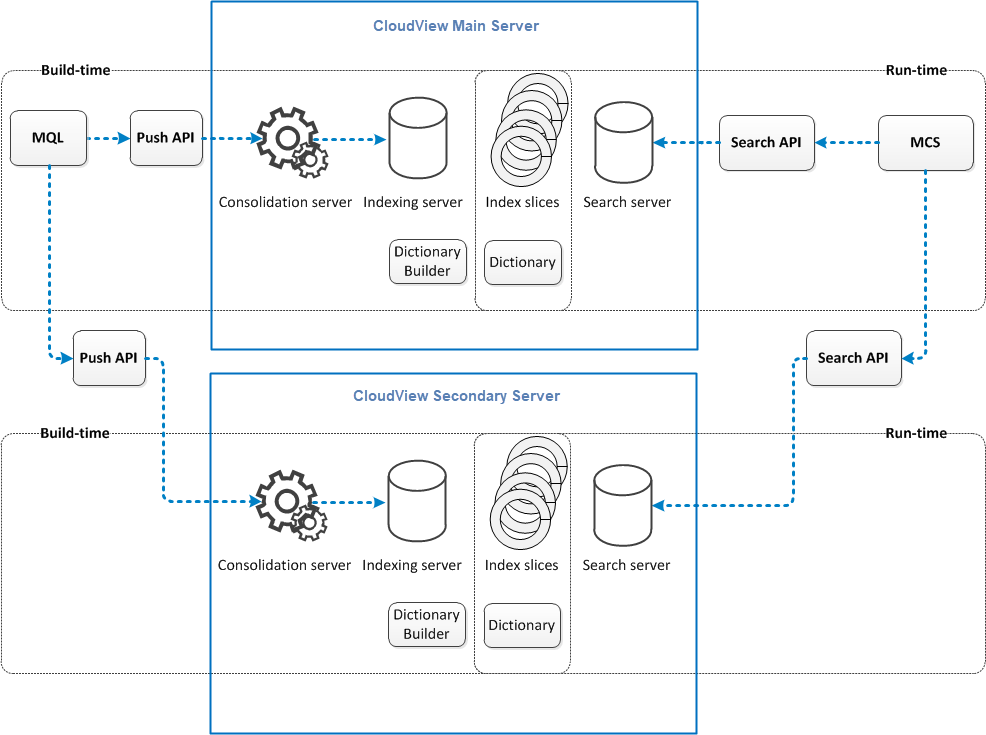
In this configuration, MQL pushes the index data to both main and secondary indexing servers. MQL detects if either server is down and only pushes changes to the server that is up. Once
the "downed" server recovers, the MQL detects that the servers have different index content and performs a separate crawl to
index the missing data on the previously "downed" server.
At run time, the Search API code that runs in the Main Collaboration Server (MCS) determines
which CloudView server is most up to date. It sends the query request to that server. To determine which
server is most up to date, a number called a "checkpoint" is stored at indexing time. Then
at search time, the MCS gets the checkpoint value of each server, and the server with the
highest checkpoint number is the server that is used. If both servers are equally up to
date, a random selection sends the requests across both servers.
At partial-index time, the build code asks each indexing server for its checkpoint. If they are
not equal, the servers do not have equal index content and one server is behind the other.
This can happen if a server goes down or is rebooted. In this case, the MQL process performs two different queries to the database to calculate the objects to index.
The MQL process pushes these objects independently to each indexing server to update them with
the correct data. At the end of this update, the 3DSpace Index resynchronizes both indexing servers, so the next partial
update will detect that both servers have equal content.
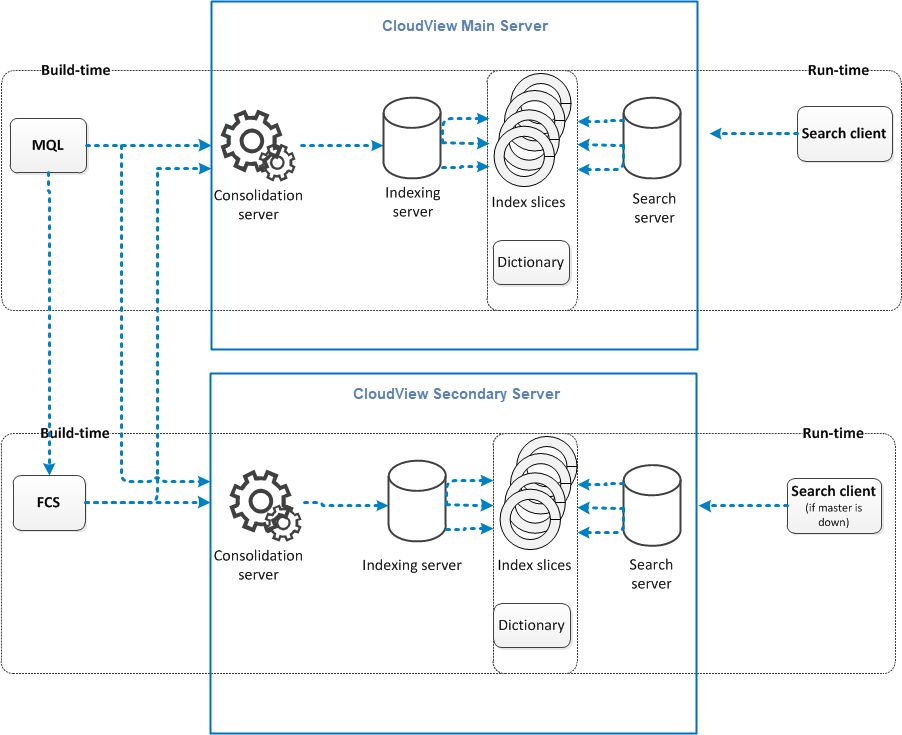
The following schema represents high availability made with a File Collaboration Server (FCS).
In that case, it is the FCS that handles file conversion, not the Consolidation Server
(which only receives metadata).